Search Sharding Architecture
Search sharding distributes a large inverted index across multiple physical nodes so that no single machine must store or search the entire document corpus, enabling horizontal scaling of both index capacity and query throughput.
Search sharding distributes a large inverted index across multiple physical nodes so that no single machine must store or search the entire document corpus, enabling horizontal scaling of both index capacity and query throughput.
How search sharding works
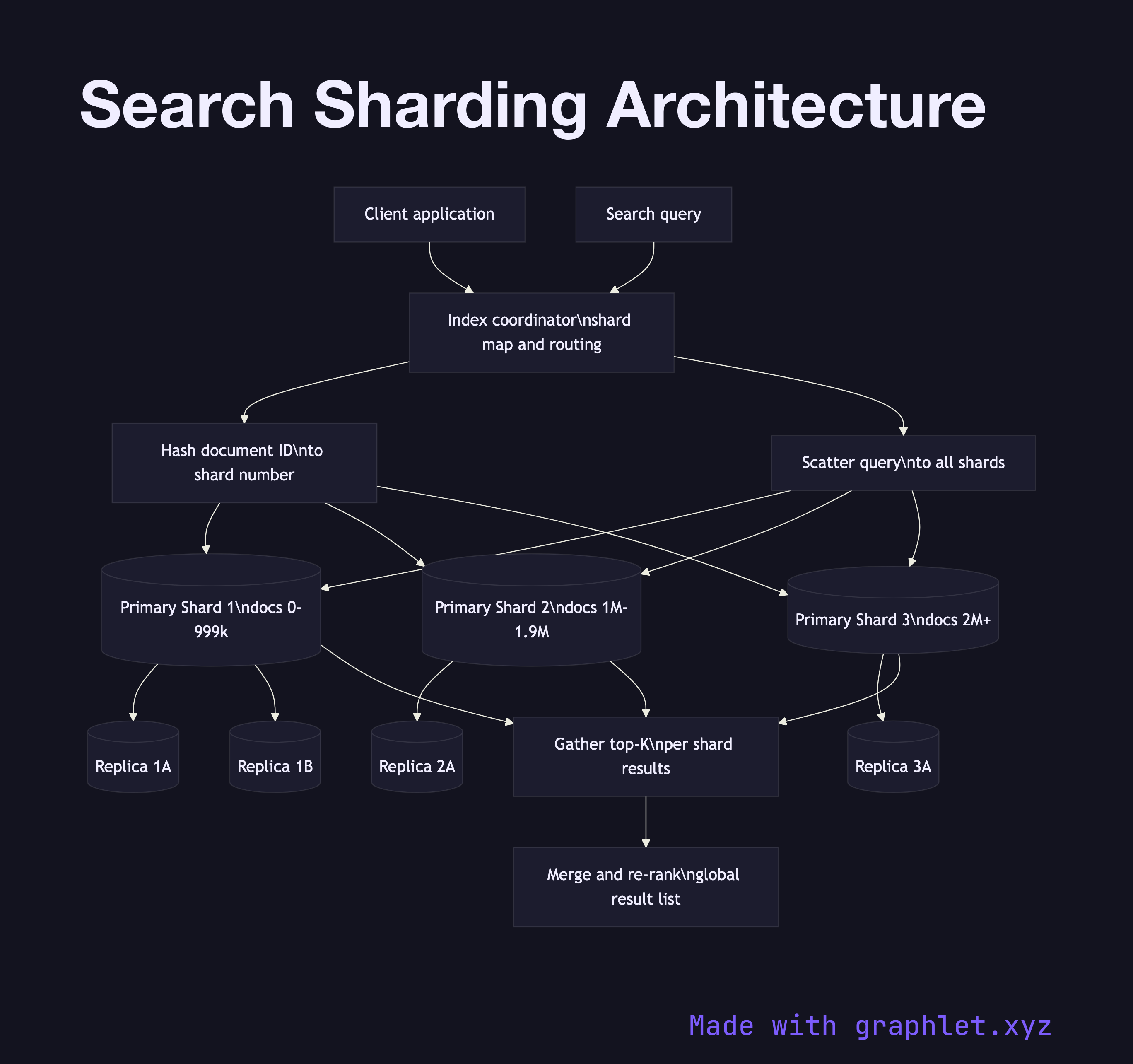
Index coordinator is the entry point for both indexing writes and search queries. It maintains the shard map — a table that records which shard ID owns which subset of the document space — and routes operations to the correct shards.
Shard allocation determines how documents are assigned to shards. The most common strategy is hash-based routing: a hash function is applied to the document ID (or a nominated routing field like tenant ID), and the result modulo the shard count yields a shard ID. Range-based partitioning is used when locality matters — for example, assigning documents by publication date to allow efficient time-range pruning.
Primary shards hold the authoritative copy of the index for their partition. Each primary shard is an independent Lucene index instance. During indexing, the coordinator sends the document to the correct primary, which writes it to a local segment and acknowledges once durable.
Replica shards are copies of primaries that serve read (search) traffic and provide failover. In Elasticsearch, each primary has N configurable replicas. The coordinator can route search requests to any replica, spreading query load across the replica set. If a primary fails, a replica is promoted — a process analogous to Database Replication failover.
Scatter-gather query execution fans a search request out to all relevant shards simultaneously (or a subset for filtered queries). Each shard executes the query locally and returns a top-K list. The coordinator merges the per-shard results, re-scores globally, and returns the final list to the Search Query Processing layer. Adding shards scales the corpus size linearly while keeping per-shard query latency roughly constant — the main lever for search infrastructure growth.