Search Result Caching
Search result caching stores the serialized output of expensive query executions so that identical or near-identical queries can be served directly from memory without touching the index, reducing latency and compute cost for popular queries.
Search result caching stores the serialized output of expensive query executions so that identical or near-identical queries can be served directly from memory without touching the index, reducing latency and compute cost for popular queries.
How search result caching works
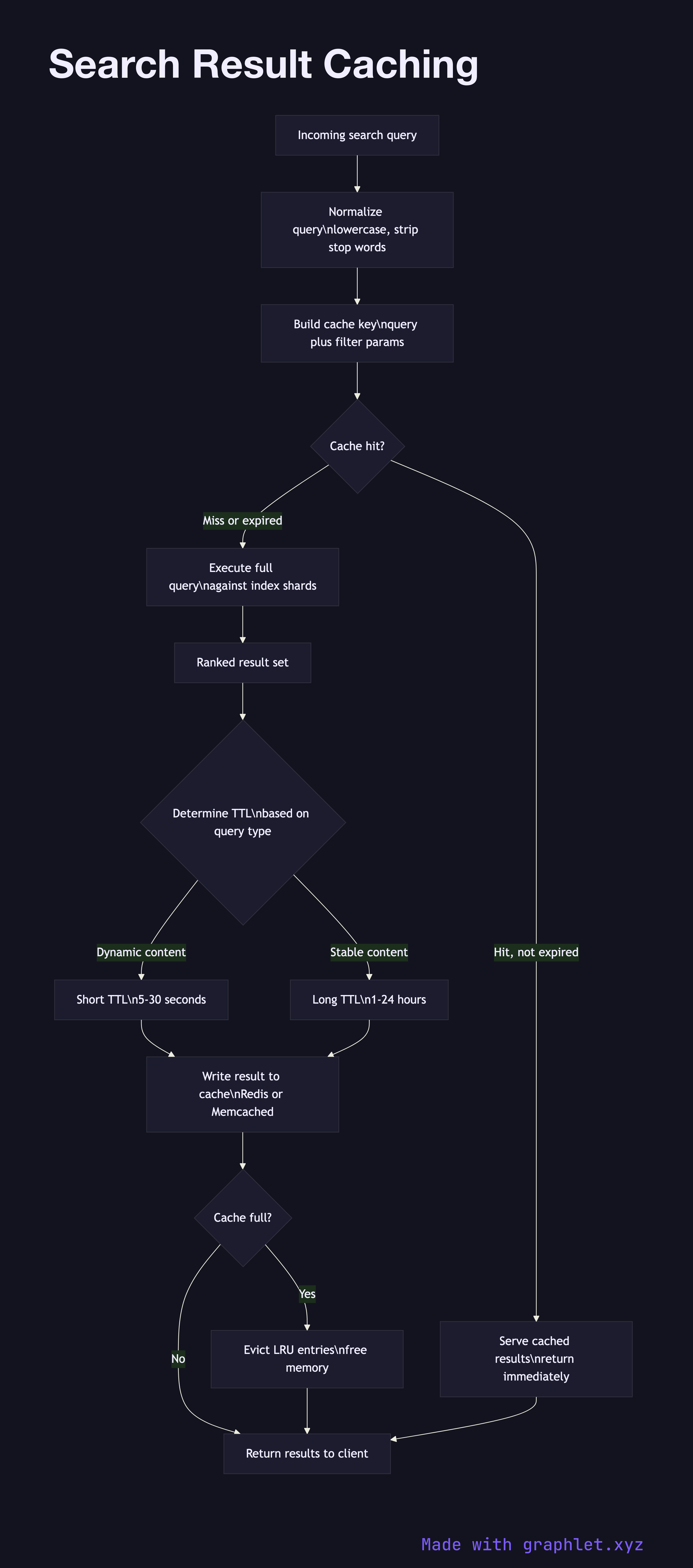
Query normalization is the first step before any cache interaction. The raw query string is lowercased, whitespace-collapsed, and stop words may be stripped to increase the chance of a cache key match across minor variations. For example, "Best Running Shoes" and "best running shoes" should resolve to the same cache key.
Cache key construction combines the normalized query string with any parameters that affect the result set: page number, language, geographic region, safe-search flag, and sort order. Personalization parameters are typically excluded from the key to allow sharing a cached result across users.
Cache lookup checks a fast in-memory store — Redis or Memcached are common choices — using the cache key. If a valid, non-expired entry exists, the cached result is returned immediately. This is a read path that bypasses the entire Search Query Processing scatter-gather phase.
Cache miss handling sends the query through the full execution pipeline: query parsing, rewriting, shard fan-out, scoring, and ranking. This is the expensive path, often taking 50–200ms depending on corpus size.
Cache write stores the result under the cache key with a TTL. TTLs are tuned by query category: highly dynamic results (breaking news, stock prices) get short TTLs of a few seconds; stable informational queries can be cached for hours. Invalidation on index updates is an alternative but operationally complex approach.
Cache eviction uses an LRU (Least Recently Used) or LFU (Least Frequently Used) policy to reclaim memory when the cache is full, retaining the most valuable entries. Cache hit rate and latency percentiles are tracked through the Search Analytics Pipeline to guide capacity and TTL tuning decisions.